In früherer Zeit war diese Funktion vermutlich eher selten von Nutzen, aber da sich der physikalische Grundaufbau von x86-Prozessoren in den letzten Jahren stark geändert hat kann man heute froh sein das es diese API-Funktion gibt. Die Rede ist von der sogenannten Prozessaffinität: Damit kann man bestimmen auf welchem logischen Prozessor ein Task ausgeführt werden soll.
Wofür man das gebrauchen könnte wird schnell klar sobald man darüber nachdenkt, wie heutige CPUs funktionieren (auch ARM). Vor allem bei Intel gibt es mittlerweile „Performance“- und „Effizienzkerne“. Bei AMD gibt es Modelle wie beispielsweise den Ryzen 9 5900X bzw. 5950X*, in denen zwei Chiplets zu je 6 bzw. 8 Kernen verbaut sind und nur das erste Chiplet die beworbenen Taktraten schafft, da eines mit besserer Siliziumqualität verbaut wurde.
Prozesse auf logische Kerne bzw. Threads zu verteilen macht normalerweise der Scheduler im Betriebssystem von selbst, also leistungshungrige Prozesse auf bekanntermaßen leistungsstarke Kerne schieben. Wenn man sich darauf aber nicht verlassen will ist es möglich das zu erzwingen.
Kompatibilität
Die zugrunde liegenden Windowsfunktionen auf Basis der „winbase.h“ existieren seit Windows XP bzw. Windows Server 2003. Die Library ist Kernel32.lib mit der dazugehörigen Kernel32.dll. Man kann die Prozessaffinität also bei allen Betriebssystemen seit inklusive Windows XP setzen.
Funktionsweise
Wichtig zu wissen ist das die Mehrheit aller x86-Prozessoren „Simultaneous Multithreading“ bzw. „Hyperthreading“ beherrschen und somit mehr als einen Thread pro physikalischen Prozessorkern ausführen können. Daher die Formulierung „logischer Prozessor“, damit ist jeder Thread und nicht jeder Kern gemeint.
Um beim Beispiel des AMD Ryzen 9 5950X zu bleiben: Diese CPU hat 16 physikalische Kerne, die mit aktivem SMT 32 Threads bieten. Die Prozessaffinitätsmaske / das System sieht also wieviele CPUs?
Richtig, 32.
Das ist wichtig im Hinterkopf zu behalten. Die interne Verteilung folgt der Initialisierungslogik des Systems, also im Beispiel eines 4 Kern / 8 Thread Prozessors mit aktivem SMT:
| Physikalischer Kern | Physikalischer Thread 1 | Physikalischer Thread 2 | Logischer Prozessor, physikalisch | Logischer Prozessor, SMT |
|---|---|---|---|---|
| 0 | 0 | 1 | CPU0 | CPU1 |
| 1 | 2 | 3 | CPU2 | CPU3 |
| 2 | 4 | 5 | CPU4 | CPU5 |
| 3 | 6 | 7 | CPU6 | CPU7 |
Mit deaktiviertem SMT würde es dann so aussehen:
| Physikalischer Kern | Physikalischer Thread 1 | Physikalischer Thread 2 | Logischer Prozessor, physikalisch | Logischer Prozessor, SMT |
|---|---|---|---|---|
| 0 | 0 | – | CPU0 | – |
| 1 | 1 | – | CPU1 | – |
| 2 | 2 | – | CPU2 | – |
| 3 | 3 | – | CPU3 | – |
Manuelle Aktivierung
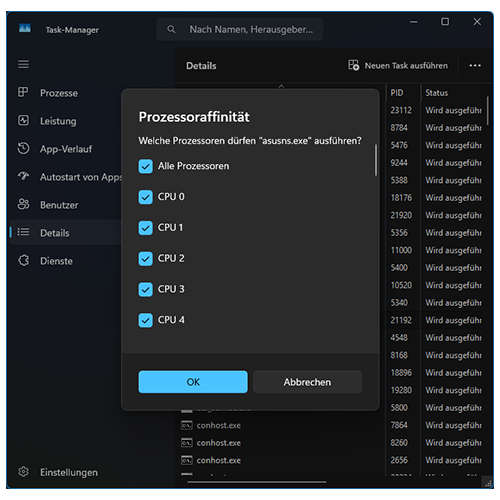
Ganz simpel: Der Prozess muss laufen – Dann startet man den Taskmanager, wechselt in die Detailansicht und rechtsklickt auf den Prozess. Ein Klick auf „Zugehörigkeit festlegen“ öffnen ein Dialogfeld in dem man exakt anhaken kann auf welchen logischen Prozessoren der Prozess laufen soll und welchen nicht:
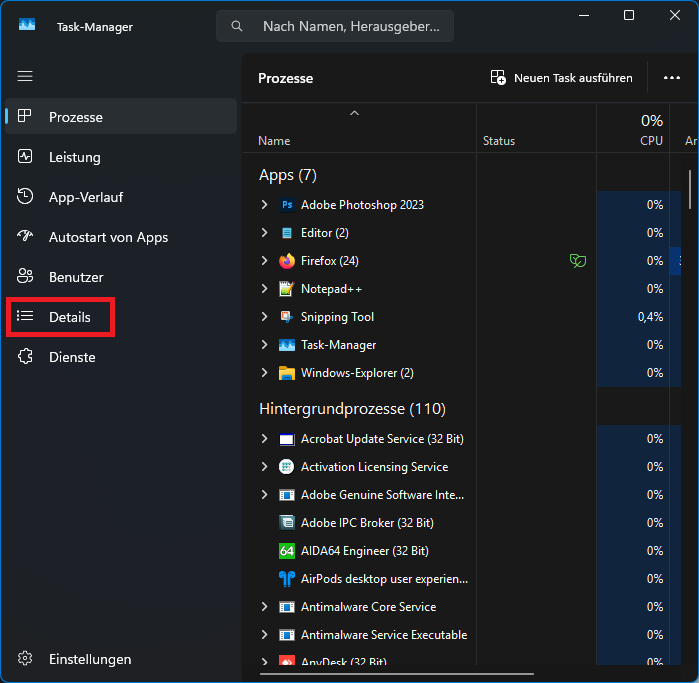
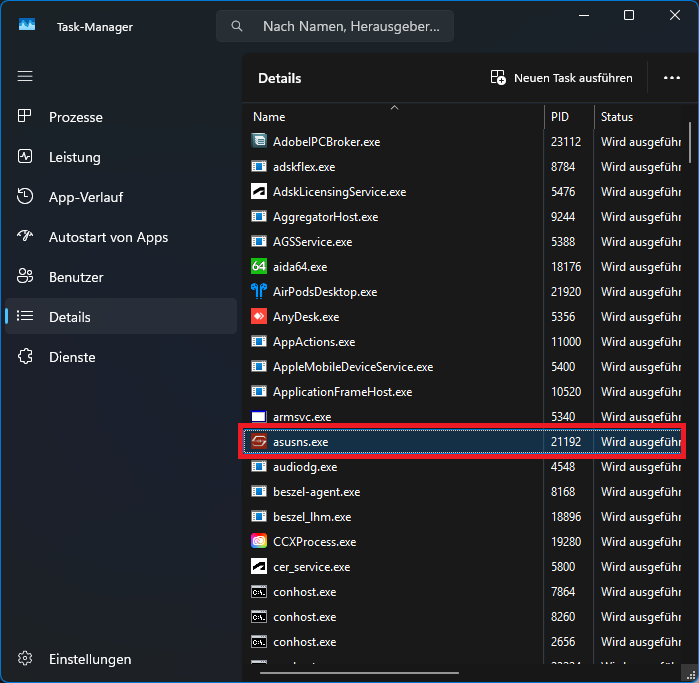
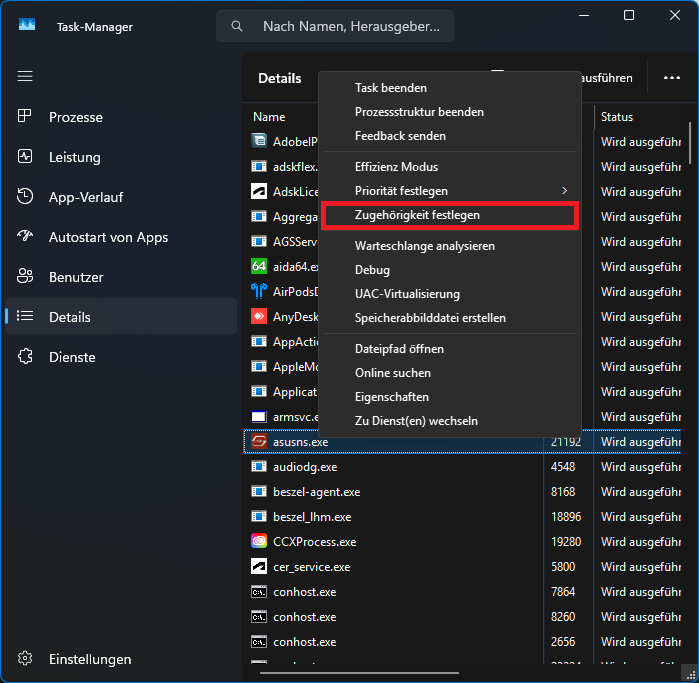
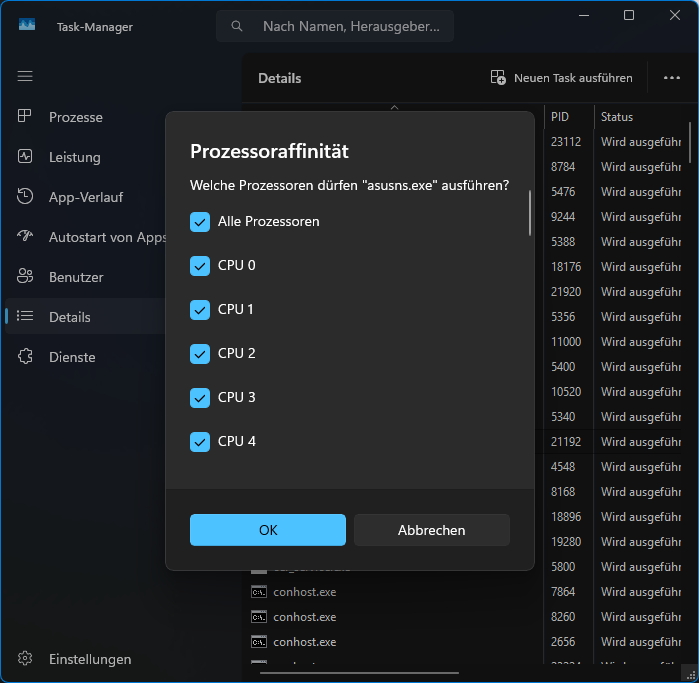
Im „Process Explorer“ von SysInternals funktioniert das ebenso über das Kontextmenü des Prozesses.
Permanente Anwendung an einem Prozess
Da wird es jetzt etwas komplexer: Die Funktion arbeitet mit Bitmasken. Um also festzulegen auf welchen genauen logischen Prozessoren ein Task laufen soll muss gerechnet werden:
| Logischer Prozessor | Dezimal | 2 x Dezimal -1 | Hexadezimal |
|---|---|---|---|
| CPU0 | 1 | 1 | 1 |
| CPU1 | 2 | 3 | 2 |
| CPU2 | 4 | 7 | 4 |
| CPU3 | 8 | 15 | 8 |
Um die Bitmaske herauszufinden ist es am einfachsten den Rechner in Windows zu starten und auf den Modus „Programmierer“ umzustellen:
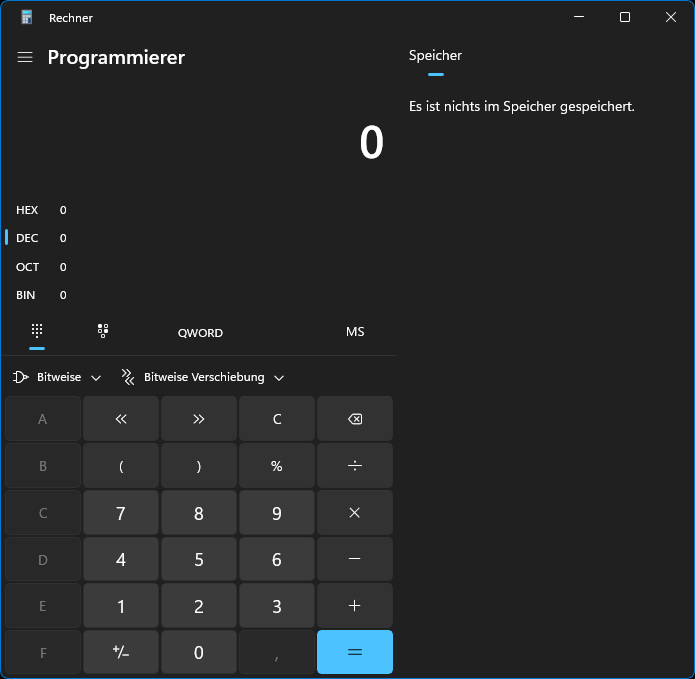
Anschließend rechnet man einfach nur die Dezimalzahlen der gewünschten logischen Prozessoren zusammen und schaut was der Wert in Hexadezimal umgerechnet ergibt. Das ist dann die nötige Bitmaske. Wenn man beispielsweise spezifisch möchte das der Prozess entweder auf Kern 0 oder Kern 3 läuft, geht das auch:
1 + 8 ergibt 9, auch hexadezimal ist das 9 und somit ist „9“ die Bitmaske.
Bei CPUs mit vielen Kernen und / oder Threads werden die Zahlen sehr schnell riesig. Das Limit, bevor NUMA-Beschränkungen auftreten und den Prozess komplexer machen liegt bei 64 logischen Prozessoren.
Tabelle bis zu 32 logische Prozessoren
Hier der Einfachheit halber eine Übersichtstabelle:
| Physikalischer Prozessor | Logischer Prozessor | Dezimal | 2 x Dezimal -1 |
|---|---|---|---|
| Kern 0 Thread 1 | CPU0 | (20) = 1 | 1 |
| Kern 0 Thread 2 | CPU1 | (21) = 2 | 3 |
| Kern 1 Thread 1 | CPU2 | (22) = 4 | 7 |
| Kern 1 Thread 2 | CPU3 | (23) = 8 | 15 |
| Kern 2 Thread 1 | CPU4 | (24) = 16 | 31 |
| Kern 2 Thread 2 | CPU5 | (25) = 32 | 63 |
| Kern 3 Thread 1 | CPU6 | (26) = 64 | 127 |
| Kern 3 Thread 2 | CPU7 | (27) = 128 | 255 |
| Kern 4 Thread 1 | CPU8 | (28) = 256 | 511 |
| Kern 4 Thread 2 | CPU9 | (29) = 512 | 1023 |
| Kern 5 Thread 1 | CPU10 | (210) = 1024 | 2047 |
| Kern 5 Thread 2 | CPU11 | (211) = 2048 | 4095 |
| Kern 6 Thread 1 | CPU12 | (212) = 4096 | 8191 |
| Kern 6 Thread 2 | CPU13 | (213) = 8192 | 16383 |
| Kern 7 Thread 1 | CPU14 | (214) = 16384 | 32767 |
| Kern 7 Thread 2 | CPU15 | (215) = 32768 | 65535 |
| Kern 8 Thread 1 | CPU16 | (216) = 65536 | 131071 |
| Kern 8 Thread 2 | CPU17 | (217) = 131072 | 262143 |
| Kern 9 Thread 1 | CPU18 | (218) = 262144 | 524287 |
| Kern 9 Thread 2 | CPU19 | (219) = 524288 | 1048575 |
| Kern 10 Thread 1 | CPU20 | (220) = 1048576 | 2097151 |
| Kern 10 Thread 2 | CPU21 | (221) = 2097152 | 4194303 |
| Kern 11 Thread 1 | CPU22 | (222) = 4194304 | 8388607 |
| Kern 11 Thread 2 | CPU23 | (223) = 8388608 | 16777215 |
| Kern 12 Thread 1 | CPU24 | (224) = 16777216 | 33554431 |
| Kern 12 Thread 2 | CPU25 | (225) = 33554432 | 67108863 |
| Kern 13 Thread 1 | CPU26 | (226) = 67108864 | 134217727 |
| Kern 13 Thread 2 | CPU27 | (227) = 134217728 | 268435455 |
| Kern 14 Thread 1 | CPU28 | (228) = 268435456 | 536870911 |
| Kern 14 Thread 2 | CPU29 | (229) = 536870912 | 1073741823 |
| Kern 15 Thread 1 | CPU30 | (230) = 1073741824 | 2147483647 |
| Kern 15 Thread 2 | CPU31 | (231) = 2147483648 | 4294967295 |
Wenn ich zum Beispiel bei einem AMD Ryzen 9 5950X möchte, das der designierte Prozess nur auf den potenziell schnelleren ersten 8 Kernen bzw. 16 Threads läuft wäre die Bitmaske rechnerisch „FFFF“ .
Scripting
Man kann den Vorgang mit Batch oder PowerShell automatisieren. Ein einfaches Beispiel in Batch:
@echo off
cd "C:\Users\Admin\Desktop\MeineSoftware"
START /min /affinity FFFF cmd /C "MeinProzess.exe -MeinParameter1 -MeinParameter2"Zusätzlich kann man auch noch gleich die Prozesspriorität setzen:
@echo off
cd "C:\Users\Admin\Desktop\MeineSoftware"
START /high /min /affinity FFFF cmd /C "MeinProzess.exe -MeinParameter1 -MeinParameter2"Mögliche Werte sind:
/low
/normal
/high
/realtime
/abovenormal
/belownormal